


Recently, our world has become inundated with Artificial Intelligence Generated Content (AIGC). AIGC is a broad term used to describe generated digital content. You may have used this technology yourself to create images, songs, videos, even simple things like emails or text. The easy-to-use platforms provided by OpenAI, Microsoft, and many others make this possible for people who aren’t technically minded.
AIGC is increasingly convincing due to higher fidelity, larger artificial intelligence (AI) models that are much better at adhering to human instruction. This paradigm is leading to situations where this content is ubiquitous and consumed without the user knowing the material is computer generated or ‘fake’.
�鶹�� Research & Development has taken steps to reduce the risk of such content by developing an AIGC detection method for images. is a joint research project undertaken by �鶹�� R&D and . has accepted our research, and it will be on show from 2-7 December.

AIGC has opened many doors for creators and academics alike; indeed, we have been developing in-house tools using facial deepfake technology to anonymise the identity of contributors for documentaries like Matched with a Predator. This approach allows viewers to see and feel the emotions and facial expressions of at-risk interviewees during crucial parts of the story whilst protecting their identities.
Though these tools have the power to do good, they can also open the doors to disinformation, targeted scams and information distortion.
We are building systems and performing research to tackle disinformation, as seen through our commitment to the C2PA standard, our previous review of deepfake detection tools and our work towards reliable deepfake detection tools.
�鶹�� News formalised this effort with the creation of �鶹�� Verify in May 2023. �鶹�� Verify tackles “fact-checking, verifying video, countering disinformation, analysing data and - crucially - explaining complex stories in the pursuit of truth”. AIGC directly affects the ability of journalists to report on what is true, so identifying this challenge, we have moved swiftly to develop tools and work with academics and reporters to reduce this risk to journalists.
�鶹�� R&D has a long history of working with and recently started a new relationship with , one of the university’s research groups, led by . For this project, I teamed up with external collaborators and , alongside our own internal team. Together we created a novel approach to help with the detection of AIGC.
To directly address the issue of AIGC, , which will feature as . This is the first time �鶹�� R&D will be published at NeurIPS, which is currently . I am planning to attend the conference along with Alex, if you wish to meet and discuss topics mentioned in this blog post or paper, please contact me at (woody.bayliss@bbc.co.uk).
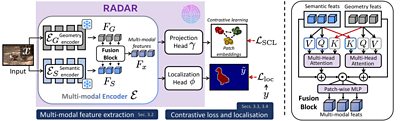
This work has also seen the creation of a dataset created by �鶹�� R&D to aid with the detection of AIGC. This dataset is being released alongside RADAR and is called .
We developed the dataset internally to act as training data for machine learning (ML) models capable of detecting AIGC. When creating the dataset, we specifically created images that were partially manipulated, aiming to improve the detection of partially manipulated images. This kind of AI image manipulation often creates more confusion because of the mixture of verifiable and fake information in the image. We’re currently working with our colleagues in R&D to release this dataset in an open-source fashion and hope to have it available in the next few weeks, well ahead of the NeurIPS conference.

We built RADAR on , allowing us to use larger models that we could not feasibly train ourselves. Our technique uses combined features from different image modalities, something only possible with the �鶹��-PAIR dataset, as no other dataset currently matches its scale and diversity. We also found that by incorporating auxiliary contrastive losses, RADAR equalled and, in many cases, exceeded the performance of current State-Of-The-Art (SOTA) academic models. We’ve shown that our model generalises effectively, performing well on AIGC outside its training data. This means that our work should apply to real-world scenarios, making it ideal for use in journalism.
To compare with SOTA models, we developed a new benchmark using the �鶹��-PAIR dataset. This benchmark contains 28 diffusion models that can be used by academics to fairly test AIGC detectors against each other.

In the future, we will continue to work with Oxford University and TVG to address pressing challenges such as misinformation, interpretability, and many other issues. We also plan to explore methods for detecting AI-generated or manipulated video, helping to spot new risks early and deal with them effectively. Alongside this, we will work closely with journalists to evaluate how these technologies can best support real-world verification workflows.
At �鶹�� R&D, we strive to bring AI technology to everyone, whether that be journalists or any creators in the media production chain, our collaborations and publications will continue to push this envelope into infinity and beyond.
Search by Tag:
- Tagged with Artificial Intelligence and Machine Learning Artificial Intelligence and Machine Learning
- Tagged with Graphics and Effects Graphics and Effects
- Tagged with Journalism Journalism
- Tagged with Data Data
- Tagged with Features Features